– 로지스틱 회귀의 규칙 적용
1. 그래디언트 업데이트 공식에 페널티 항목 반영
def __init__(self, learning_rate=0.1, l1=0, l2=0):
self.w = None
self.b = None
self.losses = ()
self.val_losses = ()
self.w_history = ()
self.lr = learning_rate
self.l1 = l1
self.l2 = l2
2. fit() 메서드에서 역 계산을 수행할 때 그래디언트에 페널티 항의 도함수를 추가합니다.
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
self.w = np.ones(x.shape(1)) # 가중치를 초기화합니다.
self.b = 0 # 절편을 초기화합니다.
self.w_history.append(self.w.copy()) # 가중치를 기록합니다.
np.random.seed(42) # 랜덤 시드를 지정합니다.
for i in range(epochs): # epochs만큼 반복합니다.
loss = 0
# 인덱스를 섞습니다
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes: # 모든 샘플에 대해 반복합니다
z = self.forpass(x(i)) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
err = -(y(i) - a) # 오차 계산
w_grad, b_grad = self.backprop(x(i), err) # 역방향 계산
# 그래디언트에서 페널티 항의 미분 값을 더합니다
w_grad += self.l1 * np.sign(self.w) + self.l2 * self.w
self.w -= self.lr * w_grad # 가중치 업데이트
self.b -= self.lr * b_grad # 절편 업데이트
# 가중치를 기록합니다.
self.w_history.append(self.w.copy())
# 안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다
a = np.clip(a, 1e-10, 1-1e-10)
loss += -(y(i)*np.log(a)+(1-y(i))*np.log(1-a))
# 에포크마다 평균 손실을 저장합니다
self.losses.append(loss/len(y) + self.reg_loss())
# 검증 세트에 대한 손실을 계산합니다
self.update_val_loss(x_val, y_val)
3. 로지스틱 손실 함수 계산에 페널티 항 추가
def reg_loss(self):
return self.l1 * np.sum(np.abs(self.w)) + self.l2 / 2 * np.sum(self.w**2)
4. 검증 세트의 손실을 계산하는 update_val_loss() 메서드에서 reg_loss()를 호출하도록 수정
def update_val_loss(self, x_val, y_val):
if x_val is None:
return
val_loss = 0
for i in range(len(x_val)):
z = self.forpass(x_val(i)) # 정방향 계산
a = self.activation(z) # 활성화 함수 적용
a = np.clip(a, 1e-10, 1-1e-10)
val_loss += -(y_val(i)*np.log(a)+(1-y_val(i))*np.log(1-a))
self.val_losses.append(val_loss/len(y_val) + self.reg_loss())
5. L1 규칙을 암 데이터세트에 적용
l1_list = (0.0001, 0.001, 0.01)
for l1 in l1_list:
lyr = SingleLayer(l1=l1)
lyr.fit(x_train_scaled, y_train, x_val=x_val_scaled, y_val=y_val)
plt.plot(lyr.losses)
plt.plot(lyr.val_losses)
plt.title('Learning Curve (l1={})'.format(l1))
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(('train_loss', 'val_loss'))
plt.ylim(0, 0.3)
plt.show()
plt.plot(lyr.w, 'bo')
plt.title('Weight (l1={})'.format(l1))
plt.ylabel('value')
plt.xlabel('weight')
plt.ylim(-4, 4)
plt.show()

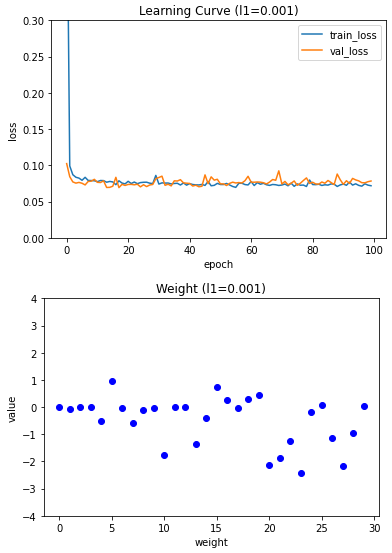
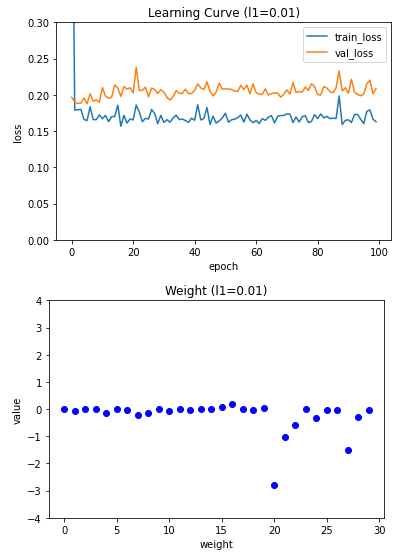
layer5 = SingleLayer(l1=0.001)
layer5.fit(x_train_scaled, y_train, epochs=20)
layer5.score(x_val_scaled, y_val)
##출력: 0.9890109890109896. L2 규칙을 암 데이터세트에 적용
l2_list = (0.0001, 0.001, 0.01)
for l2 in l2_list:
lyr = SingleLayer(l2=l2)
lyr.fit(x_train_scaled, y_train, x_val=x_val_scaled, y_val=y_val)
plt.plot(lyr.losses)
plt.plot(lyr.val_losses)
plt.title('Learning Curve (l2={})'.format(l2))
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(('train_loss', 'val_loss'))
plt.ylim(0, 0.3)
plt.show()
plt.plot(lyr.w, 'bo')
plt.title('Weight (l2={})'.format(l2))
plt.ylabel('value')
plt.xlabel('weight')
plt.ylim(-4, 4)
plt.show()

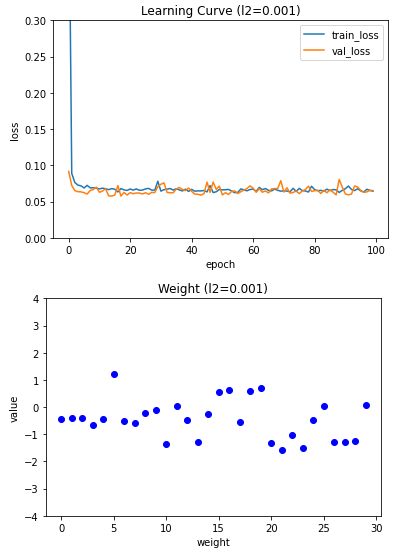
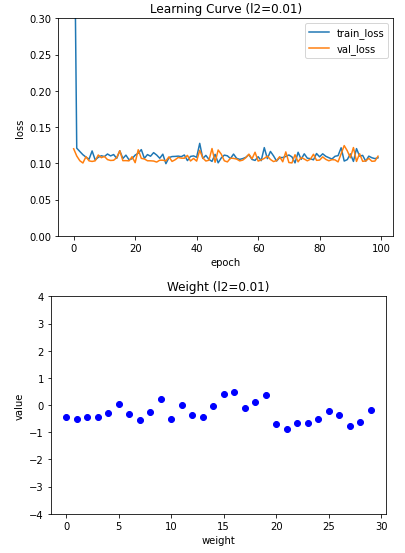
layer6 = SingleLayer(l2=0.01)
layer6.fit(x_train_scaled, y_train, epochs=50)
layer6.score(x_val_scaled, y_val)
##출력: 0.9890109890109897. SGDClassifier에서 규칙 사용
sgd = SGDClassifier(loss="log", penalty='l2', alpha=0.001, random_state=42)
sgd.fit(x_train_scaled, y_train)
sgd.score(x_val_scaled, y_val)
##출력: 0.978021978021978반응형
5-4 교차 검증, Scikit-Learn으로 해보세요
– 교차 검증의 원리
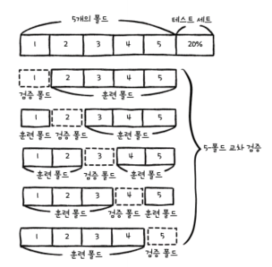

– k-겹 교차 검증 구현
훈련 세트를 동일한 크기의 k개의 접기로 나누고 각 접기를 검증 세트로 사용하고 나머지 접기를 훈련 세트로 사용하는 과정을 k번 반복하여 모델을 구축하고 평가합니다.
1. 트레이닝 세트 사용
validation_scores = ()
2. k-겹 교차 검증 구현
k = 10
bins = len(x_train_all) // k
for i in range(k):
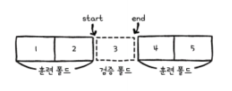
start = i*bins
end = (i+1)*bins
val_fold = x_train_all(start:end)
val_target = y_train_all(start:end)
train_index = list(range(0, start))+list(range(end, len(x_train_all)))
train_fold = x_train_all(train_index)
train_target = y_train_all(train_index)
train_mean = np.mean(train_fold, axis=0)
train_std = np.std(train_fold, axis=0)
train_fold_scaled = (train_fold - train_mean) / train_std
val_fold_scaled = (val_fold - train_mean) / train_std
lyr = SingleLayer(l2=0.01)
lyr.fit(train_fold_scaled, train_target, epochs=50)
score = lyr.score(val_fold_scaled, val_target)
validation_scores.append(score)
print(np.mean(validation_scores))
##출력: 0.9777777777777779훈련 데이터의 정규화 전처리는 분할 및 폴딩 후에 수행됩니다. -> 폴드를 분할하기 전에 전체 교육 데이터를 전처리하면 유효성 검사 폴드에서 정보가 누출됩니다.
– Scikit-Learn을 통한 교차 검증
1. cross_validate() 함수로 교차 검증 점수 계산
from sklearn.model_selection import cross_validate
sgd = SGDClassifier(loss="log", penalty='l2', alpha=0.001, random_state=42)
scores = cross_validate(sgd, x_train_all, y_train_all, cv=10)
print(np.mean(scores('test_score')))
##출력: 0.850096618357488
– 전처리 단계를 포함한 교차 검증 수행
Pipeline 클래스를 사용하여 교차 검증 수행
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pipe = make_pipeline(StandardScaler(), sgd)
scores = cross_validate(pipe, x_train_all, y_train_all, cv=10, return_train_score=True)
print(np.mean(scores('test_score')))
##출력: 0.9694202898550724print(np.mean(scores('train_score')))
##출력: 0.9875478561631581
※